Tutorial-DHN2019
Mining digital libraries
We will show how researchers within the humanities can access and use the cloud-based corpus at the National Library of Norway from within Jupyter Notebook. We cover the following topics:
- Show how copyrighted material can be utilized for corpus studies.
- Different tools built as modules over an API for defining and accessing a corpus for analysis like character modelling, collocation analysis, clustering, growth diagrams and more.
- Demonstrate the benefits of using Jupyter Notebook for researchers without programming background.
- Study the connection between texts and library metadata
A problem for many researchers is the use of copyrighted material. However, the actual text is not often required; some features of it may suffice, like bag of words, a participle count or a character model. None of these features challenge the copyright holder. A centralized repository of copyrighted material can provide feature sets that suffice for many kind of analyses.
An API can be used by researchers without programming skills, as well as programmers. While the latter need a documentation of the low-level interface to the cloud, the actual API, the former wants an accessible interface for doing corpus analysis, and Jupyter Notebook provides such an interface via top level functions and commands expressed in a programming language, e.g. Python or R.
Readymade library metadata can be integrated for building corpora based on those data, like Dewey decimal codes or topic words. We will show how metadata can be used to build, select and compare corpora. The participants will be able to build a corpus and do analysis on it.
The participants will experiment with the API, and get a hands on experience with the tools.
The repository can be used directly from a browser by following this link dhn2019 tutorial myBinder version, which uses MyBinder, documents here: Binder docs.
Schedule and Location
The tutorial take place on Tuesday March 5th, starting at 9am, in building 27, Njalsgade 136, 3rd floor room 23. You may find the building on this map, from the DHN2019 programme, marked with yellow within a red circle: 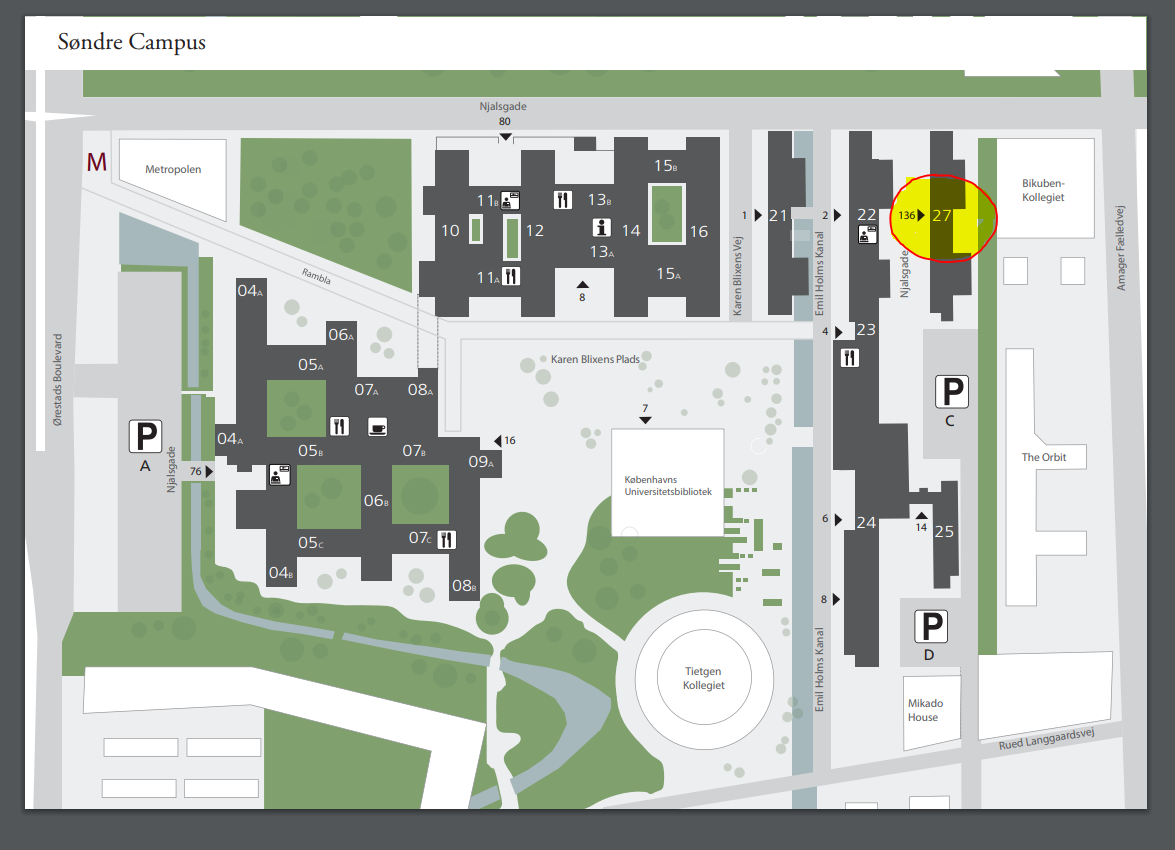 A larger map showing campus within Copenhagen:
A larger map showing campus within Copenhagen: 
A link to this page Jupyter and corpus tutorial dhn2019